SGDA with Shuffling: Faster Convergence For Nonconvex-PŁ Minimax Optimization
👥 Hanseul Cho and Chulhee Yun
🗓 📰 ICLR 2023

Poster
Abstract
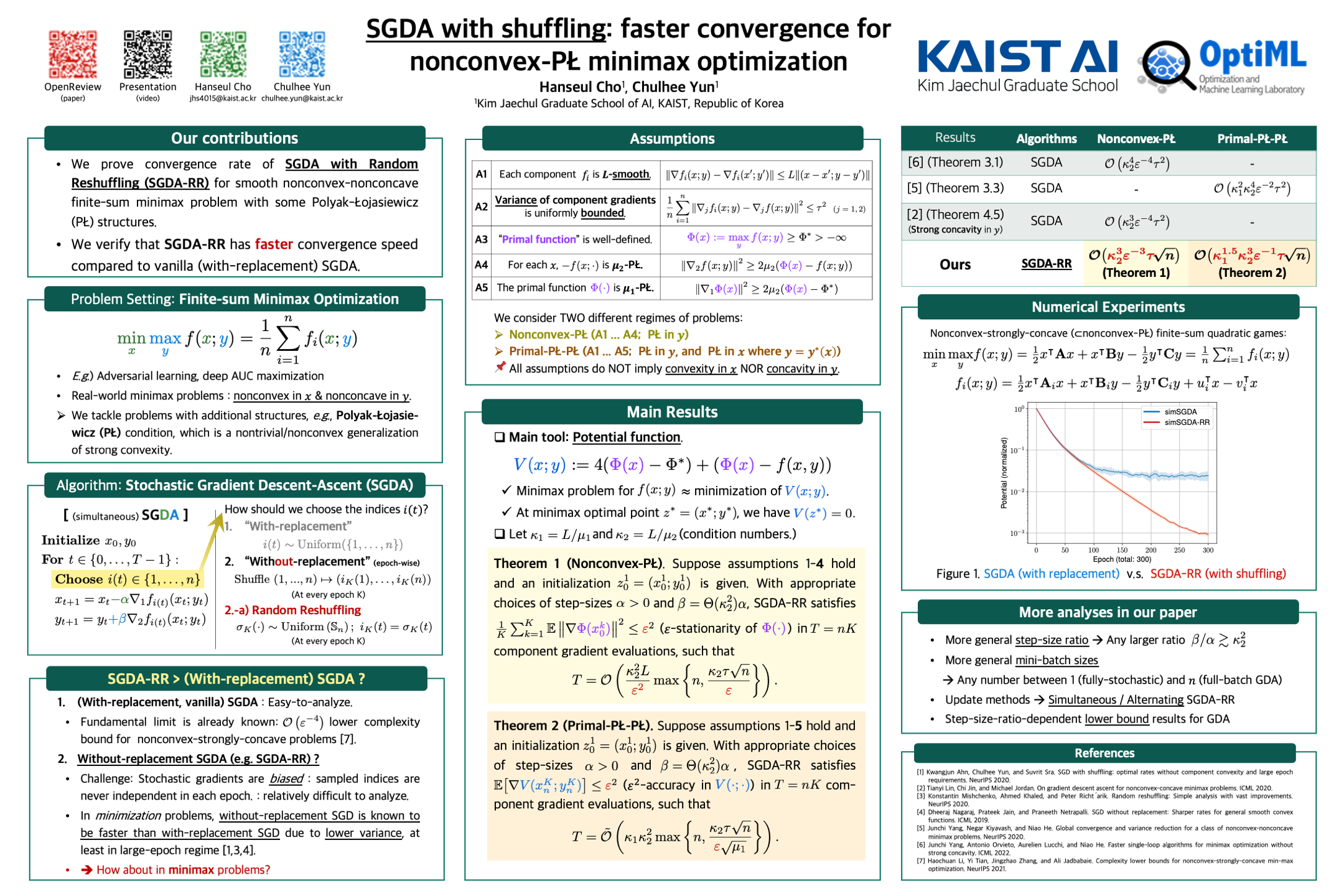
Stochastic gradient descent-ascent (SGDA) is one of the main workhorses for solving finite-sum minimax optimization problems. Most practical implementations of SGDA randomly reshuffle components and sequentially use them (i.e., without-replacement sampling); however, there are few theoretical results on this approach for minimax algorithms, especially outside the easier-to-analyze (strongly-)monotone setups. To narrow this gap, we study the convergence bounds of SGDA with random reshuffling (SGDA-RR) for smooth nonconvex-nonconcave objectives with Polyak-{\L}ojasiewicz (P{\L}) geometry. We analyze both simultaneous and alternating SGDA-RR for nonconvex-P{\L} and primal-P{\L}-P{\L} objectives, and obtain convergence rates faster than with-replacement SGDA. Our rates extend to mini-batch SGDA-RR, recovering known rates for full-batch gradient descent-ascent (GDA). Lastly, we present a comprehensive lower bound for GDA with an arbitrary step-size ratio, which matches the full-batch upper bound for the primal-P{\L}-P{\L} case.
Errata
I thank Jaeyoung Cha for pinpointing the typo below:
- Appendix F, 40p.: “$f_i(t)$” $\to$ “$f_{i(t)}(x)$”
- Corrected senctence: “Then we can write the chosen component function at iteration $t$ as ${f_{i(t)}(x)} = \frac{L}{2} x^2 − s_t \nu x$ for some i.i.d. random variable $s_t \sim \mathrm{Unif}({\pm 1})$.”
Slides
Keywords
Stochastic gradient descent-ascent(SGDA), without-replacement sampling, Random reshuffling (RR), SGDA-RR, finite-sum optimization, minimax optimization, nonconvex-PŁ, primal-PŁ-PŁ, convergence analysis