DASH: Warm-Starting Neural Network Training in Stationary Settings without Loss of Plasticity
👥 Baekrok Shin*, Junsoo Oh*, Hanseul Cho, and Chulhee Yun
🗓 📰 NeurIPS 2024 (Short version at ICML 2024 Workshop on Advancing Neural Network Training (WANT))


Main Figures
Abstract
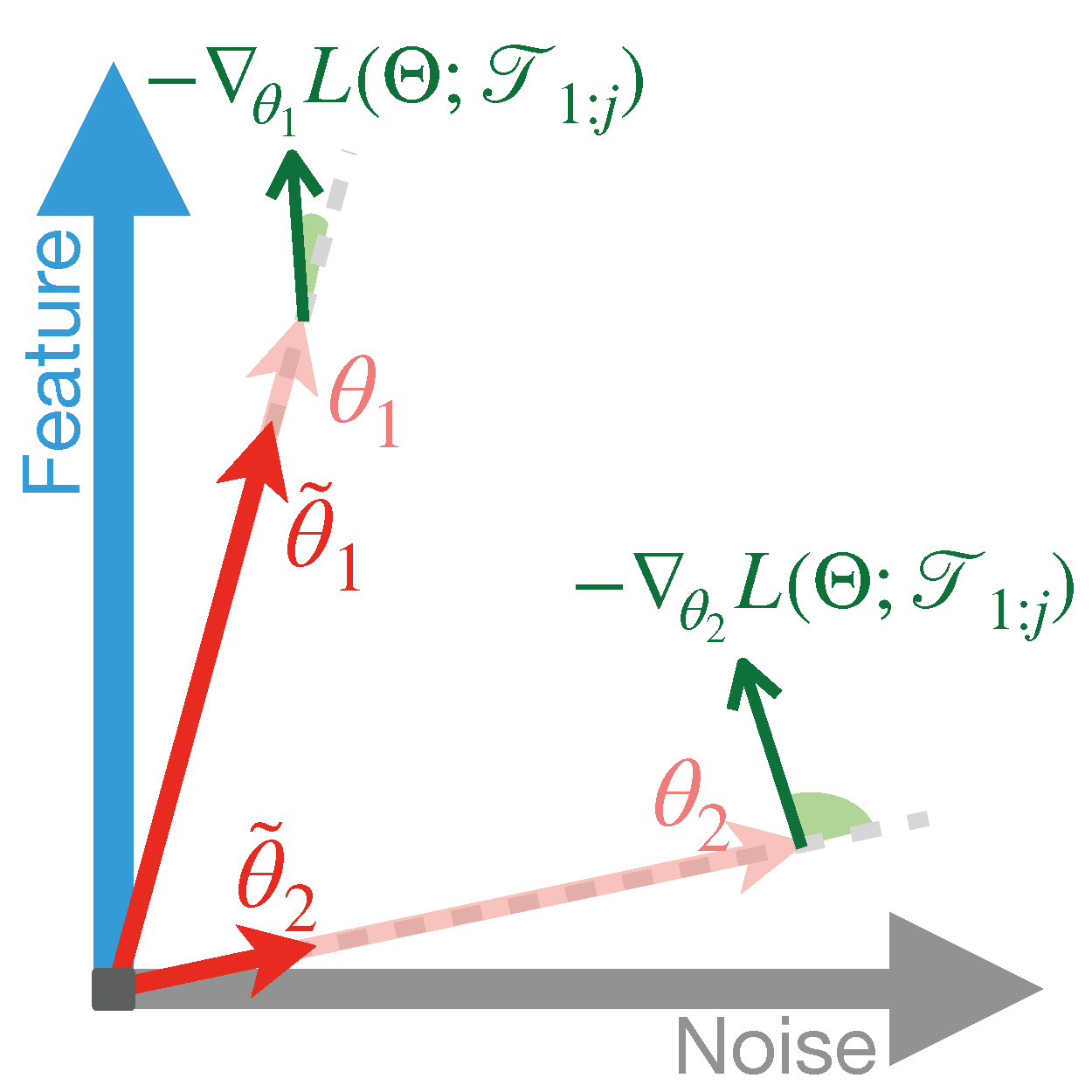
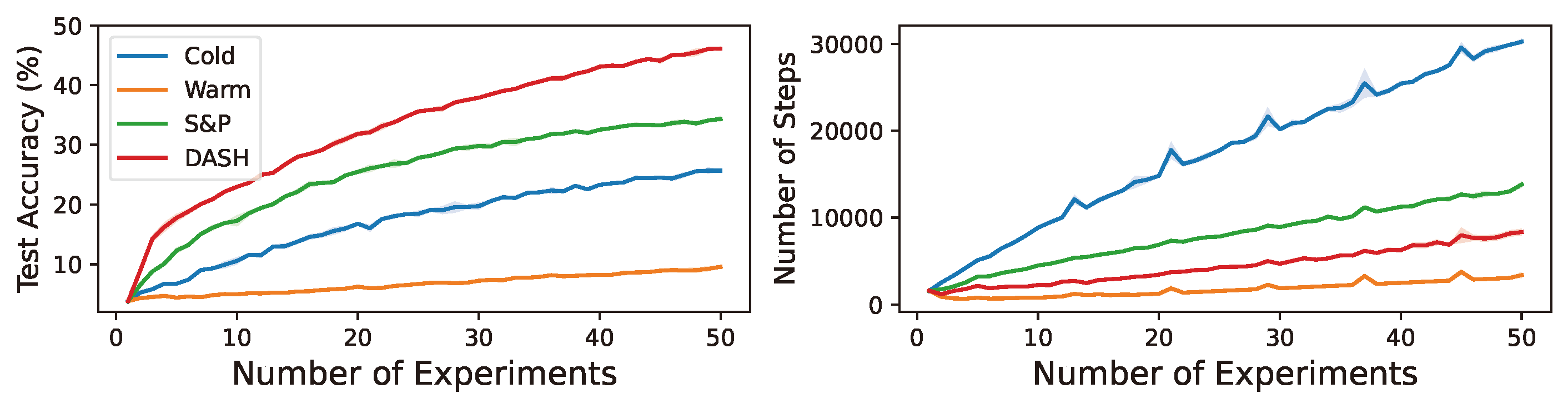
Warm-starting neural network training by initializing networks with previously learned weights is appealing, as practical neural networks are often deployed under a continuous influx of new data. However, it often leads to loss of plasticity, where the network loses its ability to learn new information, resulting in worse generalization than training from scratch. This occurs even under stationary data distributions, and its underlying mechanism is poorly understood. We develop a framework emulating real-world neural network training and identify noise memorization as the primary cause of plasticity loss when warm-starting on stationary data. Motivated by this, we propose Direction-Aware SHrinking (DASH), a method aiming to mitigate plasticity loss by selectively forgetting memorized noise while preserving learned features. We validate our approach on vision tasks, demonstrating improvements in test accuracy and training efficiency. Our codebases are in https://github.com/baekrok/DASH-Direction-Aware-SHrinking (for NVIDIA CUDA) and https://github.com/NAVER-INTEL-Co-Lab/gaudi-dash (for Intel Gaudi).