Welcome: Hanseul’s Blog 👋
I am a Ph.D. candidate at KAIST AI, fortunately advised by Prof. Chulhee “Charlie” Yun. Previously, I worked at Google NYC as an intern (SR), hosted by Srinadh Bhojanapalli.
Interested in understanding why modern ML algorithms succeed/fail and how to make them more generalizable, adaptable, and theoretically grounded.
🔬 My Research Intersets 🔭
My primary research interests lie in optimization, machine learning (ML), and deep learning (DL), especially focusing on both mathematical/theoretical analysis and empirical improvements (usually based on theoretical understanding).
During my journey to a Ph.D.👨🏻🎓, my ultimate research goal is to rigorously understand and practically overcome the following three critical
Generalizability
Generalization capability of modern language models (e.g., Transformers).
Adaptability
Learning algorithms that enable models to adapt efficiently under evolving/expanding data.
Multifacetedness
Optimization algorithms for learning problems with multiple conflicting objectives.
📋 Curriculum Vitae (CV): [PDF] | [Overleaf-ReadOnly]
📧 Primary E-mail: jhs4015 at kaist dot ac dot kr
Please don’t hesitate to reach out for questions, discussions, and collaborations! 🤗
‼️News‼️
- 🗞️
[May '26] Selected as a Gold Reviewer (top 25%: 4,439 of 17,749 reviewers) at ICML 2026 (& awarded Free Registration). - 🗞️
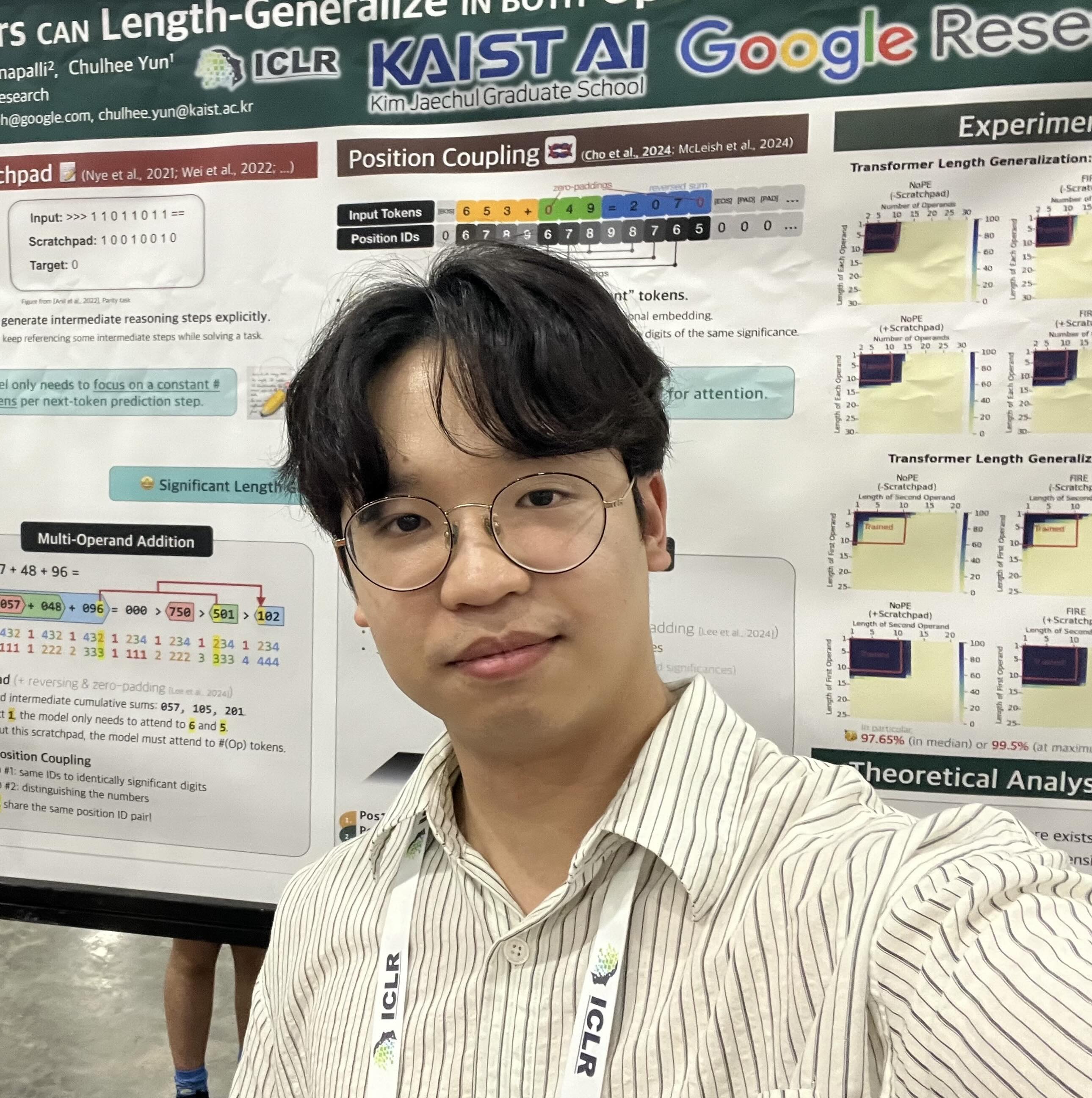
[Jan. '26] A paper is accepted to ICLR 2026! We provide a formal framework (and empirically/theoretically validate it) to study the pattern-matching behavior of LLMs on compositional tasks (e.g., multi-hop). See you in Rio de Janeiro, Brazil🇧🇷! - 🗞️
[Jun. '25] My Internship at Google has been extended to 08/22/2025. - 🗞️
[Jun. '25] I was selected as one of the Top Reviewers (top 1.88%: 206 of 10,943 reviewers) at ICML 2025!
🕰️ Past News 🕰️
- 🗞️
[May '25] I visit NYC🇺🇸 from 2025-05-02 to 2025-08-23 (see the item below). Let's grab a coffee and have a chat if you are in NYC! - 🗞️
[Feb. '25] I'll work as an Intern (Student Researcher) at Google in New York City🇺🇸! (05/05/2025–07/25/2025, Host: Srinadh Bhojanapalli) - 🗞️
[Jan. '25] Invited as a reviewer of Transactions on Machine Learning Research (TMLR). - 🗞️
[Jan. '25] Two papers got accepted to ICLR 2025! One is the sequel of our Position Coupling paper; another is about a theoretical analysis of continual learning algorithm. See you in Singapore🇸🇬! - 🗞️
[Nov. '24] An early version of our paper on theoretical analysis of continual learning is accepted to JKAIA 2024 and won the Best Paper Award (top 3 papers)! - 🗞️
[Nov. '24] I was selected as one of the Top Reviewers (top 8.60%: 1,304 of 15,160 reviewers) at NeurIPS 2024! (+ Free registration! 😎) - 🗞️
[Sep. '24] Two papers got accepted to NeurIPS 2024! One is about length generalization of arithmetic Transfomers, and another is about mitigating loss of plasticity in incremental neural net training. See you in Vancouver, Canada🇨🇦! - 🗞️
[Jun. '24] An early version of our paper on length generalization of Transformers got accepted to the ICML 2024 Workshop on Long-Context Foundation Models! - 🗞️
[May '24] A paper got accepted to ICML 2024 as a spotlight paper (top 3.5% among all submissions)! We show global convergence of Alt-GDA (which is strictly faster than Sim-GDA) and propose an enhanced algorithm called Alex-GDA for minimax optimization. See you in Vienna, Austria🇦🇹! - 🗞️
[Sep. '23] Two papers are accepted to NeurIPS 2023! One is about Fair Streaming PCA and another is about enhancing plasticity in RL. See you in New Orleans, USA🇺🇸! - 🗞️
[Jan. '23] Our paper about shuffling-based stochastic gradient descent-ascent got accepted to ICLR 2023! - 🗞️
[Nov. '22] An early version of our paper about shuffling-based stochastic gradient descent-ascent is accepted to 2022 Korea AI Association + NAVER Autumnal Joint Conference (JKAIA 2022) and selected as the NAVER Outstanding Theory Paper (top 3 papers)! - 🗞️
[Oct. '22] I am happy to announce that our very first preprint is now on arXiv! It is about convergence analysis of shuffling-based stochastic gradient descent-ascent. - 🗞️
[Feb. '22] Now I am part of OptiML Lab of KAIST AI.
👀
